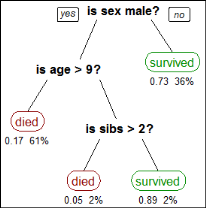
A decision tree predicts the class of an object based on the object’s attributes. For example, you can use a decision tree to predict whether a passenger on the Titanic survived, based on the passenger’s gender, age, and number of siblings, as shown in Figure 6-11. The numbers under each leaf show the probability of survival for a passenger with the specified attributes and the percentage of passengers represented by the leaf. Figure 6-11 tells us:
|
Figure 6-11
|
Figure 6-14 shows a decision tree that predicts whether a worker is low income, medium income, or high income, based on the worker’s occupation and gender.
A confusion matrix tabulates the results of a predictive algorithm. Each row of the matrix represents an actual class. Each column represents a predicted class. For example, consider a classification system that has been trained to distinguish between cats, dogs, and rabbits. Figure 6-12 shows how frequently the predictive algorithm correctly classifies each type of animal. The sample contains 27 animals: 8 cats, 6 dogs, and 13 rabbits. Of the 8 cats, the algorithm predicted that three are dogs, and of the six dogs, it predicted that two are cats and one is a rabbit. The confusion matrix shows that the algorithm is not very successful distinguishing between cats and dogs. It is, however, successful distinguishing between rabbits and other types of animals, misclassifying only two of 13 rabbits. Correct predictions are tallied in the table’s diagonal. Non-zero values outside the diagonal indicate incorrect predictions.
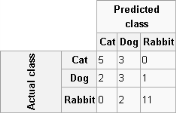
|
2
|
|
6
|
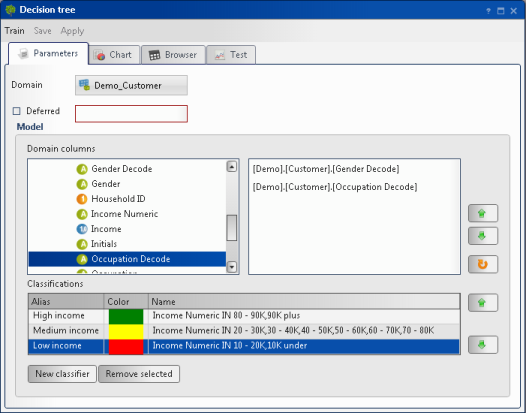
Create the remaining classifications. Figure 6-13 shows three classifications: High income, Medium income, and Low income.
|
|
Figure 6-13
|
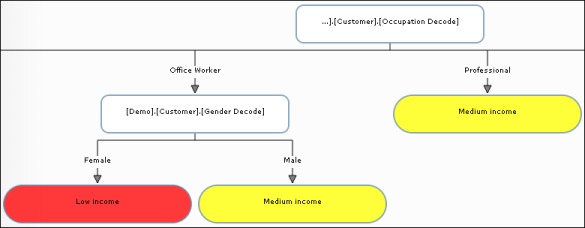
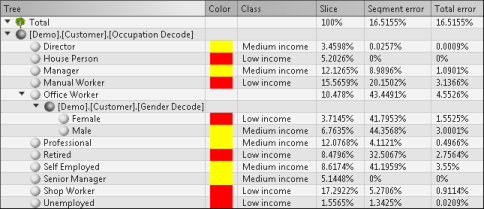
Figure 6-14 shows part of a decision tree for the Customer table domain with domain columns Occupation Decode and Gender Decode. The decision tree predicts whether a worker is low income, medium income, or high income, based on the worker’s occupation and gender. For professionals, the income classification does not depend on gender. For office workers, however, the classification for men is medium income, while the classification for women is low income.
|
Figure 6-14
|
|
8
|
Expand the tree. Figure 6-15 shows a tabular representation of the decision tree, shown graphically in Figure 6-14.
|
|
Figure 6-15
|
|
10
|
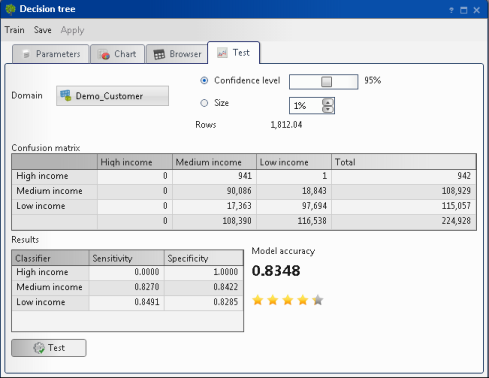
In Test, choose Test. Figure 6-16 shows the test results.
|
|
Figure 6-16
|
