The mapping process requires defining the source and the target data. The software allows you to validate the data connection and create the table column definitions. You can automatically import the target table structure from the source file or manually create the column definitions. When the table structure does not map the source file data precisely, the loading process cannot identify the data to load for each table column and finishes unsuccessfully.
To map data from files you need to know how to do the following:
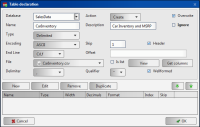
To define the target database and table, and the way the data is loaded, you must define the following information, as shown in Figure 3‑27:
Figure 3‑27 Creating a table mapping to a file
Database
Type a name for the target database, or select a listed database name.
Name
Type a unique name for a target data table.
Description
Optionally, type characters that describe the target data table.
Action
Select one of the following load operation types:
Create
Adds a new table and overwrites any content stored in an existing table, using the displayed table name.
Append
Adds records to any existing table that uses the displayed table name.
Overwrite
Choose this option when the loading transaction overwrites the target table.
Ignore
Choose this option when you must exclude the transaction from the load process
Fail on error
Choose this option by toggling on or off the corresponding check-box. When the box is checked, any exception in the loading process will cause it to stop.
Defining a source file format
Based on your knowledge of source file properties, select formatting properties that most closely match those of the source file. More accurately selecting source file properties minimizes manual definition of target table properties.
Type
Select the file type. The files can be flat, or delimited. The flat files do not have delimiters and qualifiers.
Encoding
Select an encoding type from the list. Table 3‑2 lists and describes the file encoding types that BIRT Analytics supports.
Table 3‑2 Supported encoding
Encoding
Description
ASCII
American Standard Code for Information Interchange
CP1252
Windows Latin-1
BIG5
Chinese character encoding method used in Taiwan, Hong Kong, and Macau for Traditional Chinese characters
BIG5-HKSCS
Standard supplementary character set used for information exchange in Chinese between the public and the Hong Kong SAR Government
CP1252
Windows Latin-1
GB18030
Chinese government standard describing the required language and character support necessary for software in China
GB2312
Official character set of the People’s Republic of China, used for simplified Chinese characters
GBK
An extension of the GB2312 character set for simplified Chinese characters, used in the People’s Republic of China
ISO-8859-1
ISO 8859-1, Latin Alphabet No. 1
ISO-8859-2
Latin Alphabet No. 2
ISO-8859-3
Latin Alphabet No. 3
ISO-8859-4
Latin Alphabet No. 4
ISO-8859-5
Latin/Cyrillic Alphabet
ISO-8859-6
Latin/Arabic Alphabet
ISO-8859-7
Latin/Greek Alphabet
ISO-8859-8
Latin/Hebrew Alphabet
ISO-8859-9
Latin Alphabet No. 5
ISO-8859-13
Latin Alphabet No. 7
ISO-8859-15
Latin Alphabet No. 9
UTF8
8-bit UCS Transformation Format
UTF16
16-bit UCS Transformation Format, byte order identified by an optional byte-order mark
UTF16LE
16-bit Unicode Transformation Format, little‑endian byte order
UTF16BE
16-bit Unicode Transformation Format, big‑endian byte order
WINDOWS-1252
Windows Latin-1
End Line
Select an end-of-line character from the list. Table 3‑3 lists and describes the end-of-line characters and results supported by BIRT Analytics Loader.
Table 3‑3 End-of-line characters and results
End-of-line character
Result description
CRLF
Carriage return and line feed
CR
Carriage return only
LF
Line feed only
File
Select a source file name from the list.
Delimiter
Select the character used to delimit or separate values in a delimited file only. The following delimiter characters are supported by BIRT Loader:
, ->| | : ; @ # " + - = '
Header
Select Header option if the source file includes information in a header. A file header contains multiple column names, each separated by a delimiter character.
Skip
In Skip, type a number that sets how many blank rows to insert between header information and record information in a file. If you select Header option, 1 appears in Skip by default.
Offset
Define the initial position of each column when the file format is flat file.
Qualifier
Select a qualifier character. BIRT Loader supports the following qualifier characters:
" ' ~
Choose None, if the file format does not use a qualifier.
Wellformed
Select the Wellformed option to enforce verification that each record contains all columns.
Wellformed explanation:
“Checked” - indicates the same number of columns in data source and table definition
“Unchecked” - extra columns are ignored and Null values are set for missing columns
Defining table columns
To automate defining the structure of a target data table, extract data from a source data file, using Get columns. During extraction, Get columns adds column type and index information to each data element. You must review and edit, as necessary, the type and index information for every column. Consider removing the index from every column not strictly requiring an index. Removing unnecessary indexes speeds data load and analysis processes, but may limit performing aggregation and link operations. These operations require indexed columns.
View
Choose View to see the data in the file and check the connectivity to the file.
Get columns
Choose Get columns to get the column names and type automatically from the source file.
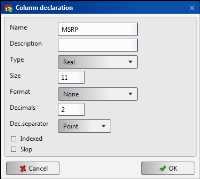
To create a target data table manually, define each column using the New, Edit, Remove, and Duplicate options. While you edit the structure of a target data table, use Get columns to retrieve existing column information, then use Edit to make modifications. To create a new column, choose New, then provide information using Column Declaration, as shown in Figure 3‑28.
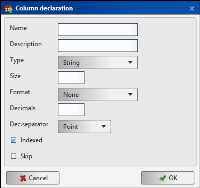
Figure 3‑28 Creating a new column
New
Creates a new column in the target table
Name
Enter the name of the column.
Description
Enter a description of the column.
Type
Enter the data type. The supported data types are described in Table 3‑4.
Table 3‑4 Data types
Type
Description
String
A sequence of characters, up to 1024.
Integer
Integer (whole number) data from -2^31 (-2,147,483,648) through 2^31 - 1 (2,147,483,647).
Longint
Integer (whole number) data from -2^63 (‑9,223,372,036,854,775,808) through 2^63-1 (9,223,372,036,854,775,807).
Real
Floating precision number data with the following valid values: ‑3.40E + 38 through -1.18E - 38, 0 and 1.18E - 38 through 3.40E + 38.
Date
The default format is mm_dd_yyyy, where the date separator can be slash (/), comma (,), period (.), or no separator.
Datetime
Date and time data from January 1, 1400, through December 31, 9999, with an accuracy of three-hundredths of a second, or 3.33 milliseconds. The default format is yyyy_mm_dd_hh_MM_ss.
Time
The default format is hh_MM_ss.
Unicode
A sequence of Unicode characters, up to 1024.
Size
The size of the column in characters, or digits.
Format
The format of the columns of type Date, Datetime, and Time.
Decimals
The number of digits to the right of the decimal point, or comma. Applies for data of type Real.
Decimal separator
You can choose Point or Comma to visualize a decimal separator. Applies for data of type Real.
Indexed
Indicates if the column is an index.
Skip
Select Skip to exclude a new column from the load process.
Edit
Opens the Table Declaration editor for a single column.
Remove
Removes a column from the target table.
Duplicate
Creates a new column by copying the properties of an existing column.
How to map data from a CSV file
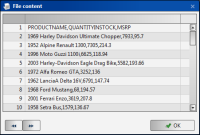
The following procedure assumes that you have created a data file connection. The procedure uses as an example, a CSV file having the following structure:
PRODUCTNAME,QUANTITYINSTOCK,MSRP
1969 Harley Davidson Ultimate Chopper,7933,95.7
1952 Alpine Renault 1300,7305,214.3
1 In Options, choose New from file.
2 In Table Declaration, set properties for the target database, as shown in Figure 3‑29.
1 In Database, type a database name. Alternatively, select an existing database name from the list of target databases.
2 In Name, type the name a target table to which you will map data. For example, CarInventory.
3 In Description, type characters that describe information the table will contain, such as Car Inventory and MSRP.
4 In Action, select Create.
5 Select Overwrite.
Figure 3‑29 Defining file structure
3 Select options that match properties of the source file, as shown in Figure 3‑29.
1 In Type, select Delimited.
2 In Encoding, select ASCII.
3 Select Header. In this example, 1 appears in Skip. Edit the value in Skip to match the number of header rows in the source data file.
4 In End Line, select CrLf.
5 In File, select a source file name from the list.
6 In Delimiter, select comma (,).
7 In Qualifier, select ".
8 Select Wellformed.
4 Choose View to validate the data connection. The file content appears, as shown in Figure 3‑30. Choose OK.
Figure 3‑30 Viewing file content
5 Choose Get columns to import the file metadata.
During the metadata import process, Get columns reads column name information from the header row in the source file, determines a type for each column, and indexes each column.
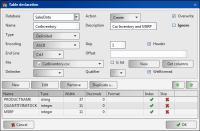
Definitions for each new column created in the target table appear listed in Table Declaration, as shown in Figure 3‑31.
Figure 3‑31 Getting column definitions
6 To modify properties for a column, select a listed column definition and choose Edit.
1 In Column Declaration, select or modify any available properties.
2 To remove index information from a column, deselect Indexed.
3 To exclude a column from loading, select Skip.
4 Choose OK.
For example, change the type of the MSRP column from Integer to Real, and set the column to not indexed, as shown in Figure 3‑32.
Figure 3‑32 Editing column definition properties
7 To close a selected database table, in Table Declaration, choose OK.
8 In Project, choose Save. Choose Yes to confirm saving the script for the current project, as shown in Figure 3‑33.