Understanding process flow in an iHub cluster
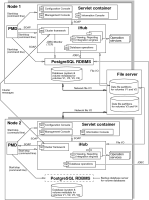
Figure 1‑2 illustrates the iHub process architecture for a clustered, two‑node, four-volume, OOTB database configuration. A node is a machine running an iHub instance.
Figure 1‑2 iHub RDBMS process architecture for a clustered, two‑node, four‑volume, OOTB database
The iHub OOTB PostgreSQL RDBMS starts multiple instances to handle connections for running queries that access metadata. In database jargon, PostgreSQL uses a process-per-user, client/server model. For more information, refer to the PostgreSQL documentation at the following URL:
http://www.postgresql.org/docs/8.4/static/connect-estab.html
An iHub administrator adds a node to a cluster to scale iHub System to the necessary processing requirements. There are two methods of adding a node to the cluster:

Perform an automated, custom installation, using the wizard-driven installation program.
Perform a manual installation, using the script-driven, cloud deployment package, and a prepared image of an installed iHub run-time environment.
Every cluster node must have network access to the following directory and resources to join the cluster:
The shared configuration home directory
Cluster resources, such as printers, database systems, and disk storage systems
Each node gets its configuration from a template in acserverconfig.xml, which is located in a shared configuration home directory along with the license file, acserverlicense.xml.
The acserverconfig.xml file contains the server templates as well as other configuration parameters specifying the host names, volume names, port numbers, printers, and services used by nodes in the cluster. When the Process Management Daemon (PMD) starts up, it reads these configurations and exposes them to the process environment variable list. When a node joins a cluster, it configures itself using its template.
After installation and configuring the appropriate environment variables in acpmdconfig.xml, the administrator launches the installed iHub image from the command line by passing the necessary arguments or creates a script to execute the command. Nodes with the same cluster ID, running on the same sub-net, automatically detect and join each other to form the cluster. This feature is known as elastic iHub clustering.
The cluster automatically detects the on-off status of any node. Single-point node failure does not affect the availability of other nodes.
In the two-node cluster example, shown in
Figure 1‑2, client applications, such as Actuate Information, Management, and Configuration Consoles, run in a servlet container. These applications support distributing requests to multiple machines. The cluster communicates across the network using standard HTTP/IP addressing.
One or more nodes in the cluster manage the request message routing. The Process Management Daemons (PMDs) located on each node coordinate processing among available iHub services based on message type to balance load across the nodes.
This loosely coupled model provides the following improvements to intra-cluster messaging:
Each iHub node in the cluster is relatively independent and identical in terms of components and functionality. Intra-cluster messages are limited to messages for cluster membership and load balancing.
Operations like design execution and viewing typically require intermediate information from the Encyclopedia volume metadata database. This information is now directly retrieved from or updated in the RBDMS, eliminating internal messages to Encyclopedia services on other nodes.
This increased scalability of operations at the iHub level can create bottlenecks at the RDBMS level. Important factors to consider when configuring nodes and ancillary resources include estimating processing power and access to hardware and software resources, such as printers and database drivers.
iHub instances running on multiple machines maintain iHub system and Encyclopedia volume metadata in a database, which controls access to shared volume data. The volume data can be on machines that are not running iHub, but must be shared and accessible to each iHub instance.
This loosely coupled cluster model provides the following maintenance and performance benefits:
Startup and shutdown of an iHub node is fast because it is independent of the RDBMS that manages the Encyclopedia volume. An RDBMS can remain online when shutting down an iHub node. The RDBMS is available when the iHub node starts up.
Controlling the sequence of Encyclopedia volume startup is not necessary. All volumes are either already online or come online as the RDBMS starts.
Downtime to apply a patch fix patch or a diagnostic fix for an iHub node is reduced. The RDBMS, including the OOTB PostgreSQL database server, does not have to be shutdown. In an iHub cluster, the patch or diagnostic fix can be applied to one iHub node at a time.
This operational model lends itself well to grid, cloud, and other data-center types of deployments.
For more information about the cloud computing deployment option, see
Chapter 6, “Installing BIRT iHub in a cloud,” later in this book
. For more information about the cluster installation option, see Chapter 9, “Clustering,” in
Configuring BIRT iHub.