About retrying a failed job
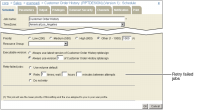
When scheduling a job, you can specify that iHub run the job again if it fails. The volume-level job retry policy specifies the default policy for all jobs on the volume. When you schedule a job, you can accept or override this policy by setting one of the following options in Retry failed jobs on Schedule—Schedule, as shown in
Figure 5‑9:

Use volume default
Use the volume-level retry settings.
Retry
n times; wait
n hours
n minutes between attempts
Specify how many times iHub should retry running the job and how long the system should wait between tries.
Do not retry
Make no retry effort.
Figure 5‑9 Selecting a job retry option
The following conditions affect a job retry policy:
Retry settings do not apply to jobs that you schedule to run right now.
For Retry N times, wait H hours M minutes between attempts.
When N is not 0 and H and M are 0, the Encyclopedia volume resubmits the job immediately after a failure.
iHub cancels a new instance of a scheduled job, with an appropriate message, if the previous instance is still retrying.
The retry count (N) for the existing instance does not increase.
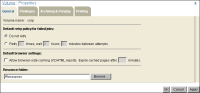
Setting the Encyclopedia volume job retry policy
You can configure a job retry policy for the Encyclopedia volume, which regulates the repeating attempts to run scheduled jobs that fail, as shown in
Figure 5‑10. Only the administrator can change the volume job retry policy.
Figure 5‑10 Specifying the default job retry policy