Preparing data for mining
BIRT Analytics supports normalization, scaling, and remapping operations that prepare a data column to meet conditions required by each data mining algorithm. Preprocessing applies a mathematical operation to values in a data column. Preprocessing a column of data values having a distribution that differs from a standard, or normal, distribution before applying a data mining algorithm can produce a more useful result. For example, you can compare data sets that have different scales and units by standardizing the data so that it falls in the 0 to 1 range. Test scores are often calibrated by percentile, with most scores falling in the 25th to 75th percentile.
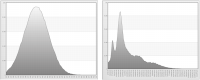
Figure 6‑1 shows the distribution of raw, or non-standardized, data for age and income. Ages fall in the 19 to 93 range, while incomes fall in the 479.79 to 111571.4 range. To compare these distributions, you must standardize the data.
Figure 6‑1 Distribution of raw data for age (left) and income (right)