Connecting to a Hadoop system
BIRT Designer provides a JDBC driver to connect to a Hadoop system through Hive. Similar to connecting to a database, you provide the URL to the Hive machine and your user credentials. You also have the option to pass MapReduce scripts to Hadoop. These scripts can be written in any programming language.
How to create a Hive data source
1 In Data Explorer, right-click Data Sources, then choose New Data Source.
2 In New Data Source, specify the following information:
1 Select Hive Data Source from the list of data source types.
2 In Data Source Name, type a name for the data source.
3 Choose Next.
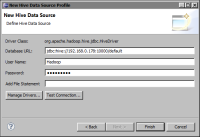
3 In New Hive Data Source Profile, specify the properties to connect to the Hive system.
1 In Database URL, type the URL to the Hive system.
2 In User Name and Password, type the user credentials to connect to the system.
3 In Add File Statement, optionally type one or more Add File statements to add script files to the Hadoop distributed cache, as shown in the following example. Separate each Add File statement with a semicolon.
add file /usr/local/hive/rating_mapper.py; add file /usr/local/hive/weekday_mapper.py;
Figure 6‑18 shows an example of properties to connect to a Hive system.
Figure 6‑18 Connection properties for a Hive system