Mapping data from a database requires that you define many of the same properties as those that you define for mapping data from files. To map data from a database, first select the target FastDB database, provide a target table name, and select a data source. You can select a data source from the data base connections you have created.
Next, define the data set to retrieve from the source database using the Table Declaration screen that appeared when you clicked on the New from database option. This is described in more detail in the Defining a data setsection.
Selecting a database in the Datasource drop-down list, provides the option to define a query that retrieves a data set. This is described in more detail in the “How to map data from a PostgreSQL database” section.
Defining a data set
To define a data set you must provide a query and set options for the query.
Query
Defines a SQL query from a relational database. You can type a query manually, and use the Get columns option to retrieve the columns from the data set.
Alternatively, you can use the View option to select tables and columns. Use the drop-down list in the Datasource field to select tables and their columns, and specify the column order using the up and down arrows.
Options
Enter the options required by the connection drivers. For example, when loading data from an Oracle database, consider including a parameter, such as PreFetchRows=10000.
The process of defining the target table structure is the same as the one discussed in “Defining table columns,” earlier in this section. While editing the structure of a target data table, use the Get columns option to retrieve existing column information, then use Edit to make modifications. To create a new column, choose New, then provide information in the Table Declaration screen, as shown in Figure 3‑31.
How to map data from a PostgreSQL database
This procedure assumes you have already created an PostgreSQL database connection.
1 Define the target FastDB database and table.
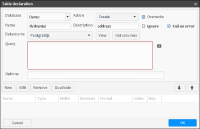
1 In the Data tab of your project, choose the New from database option to open the corresponding Table Declaration as shown in Figure 3‑31. Choose the target database from the drop-down list in the Database field.
Figure 3‑31 Mapping data from a PostgreSQL database
2 Choose “Create“ in the Action field.
3 In Name, specify the name of the target table.
4 In Description, type the table description.
5 Select the Overwrite box
2 Define the Query to extract data.
1 In Table declaration - Datasource, select a database profile.
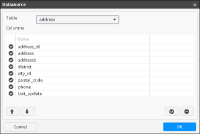
2 Choose View database structure beside the Query field. The Datasource screen appears.
In Datasource, select a table from the drop-down list. The column names appear, as shown in Figure 3‑32.
Use + and - to add or remove columns, and the up and down arrows if you need to change the column order.
In Datasource, choose OK to confirm the column definitions and generate the query.
Figure 3‑32 Selecting columns from a database table
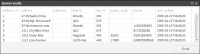
This example generates the following query:
SELECT * FROM "address"
3 In Options, specify any options you want to pass to the data driver.
3 Choose View to preview the data connection and view the data. Your query results appear, as shown in Figure 3‑33.
Figure 3‑33 Viewing data from a database
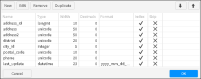
4 Choose Get columns to retrieve the columns from the target table. The column definitions appear as shown in Figure 3‑34. The types are determined automatically, and all columns are indexed by default. Get columns overwrites the existing data set, and discards your existing changes.
Figure 3‑34 Getting the column definitions from the data set
5 Edit the column declaration.
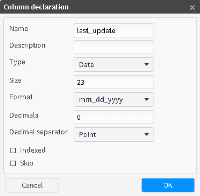
The example in Figure 3‑35 changes the format of the last_update column, and disables indexing of the column.
Figure 3‑35 Editing a Datetime column
1 Select the last_update column and choose Edit.
2 In Type, select Date format.
3 In Format, select mm_dd_yyyy.
4 Disable Indexed and choose OK.
6 Choose Save to save the project.
Managing errors in the loading process
In Data - Options you can decide to continue the loading process when errors occur.
By default, the loading process stops whenever an error is encountered. You can continue loading data when error occur using On Error. This enables the loading process to ignore any tables that generate errors during the process, leaving them to be fixed and loaded later if desired.
Ignoring errors is useful when loading high volume tables overnight.
ON ERROR Attribute
In Data - Options, choosing the “minus” symbol (in the “On error” column) beside a table row, changes the “minus” symbol to an “arrow” symbol and deactivates the default “Fail on error” setting in the list of tables to be loaded, as shown in Figure 3‑36.
Figure 3‑36 Reviewing new table entries
Double clicking on the table opens its Table declaration window where you can see that the Fail on error check-box is now “unchecked”. Clicking the “arrow” symbol changes it back to “minus” and resets the “Fail on error” setting, selecting the box again as shown in Figure 3‑37.
Figure 3‑37 Managing exceptions using the Data tab
_thumb.png)